一、抓取原理(深度抓取和廣度抓取)
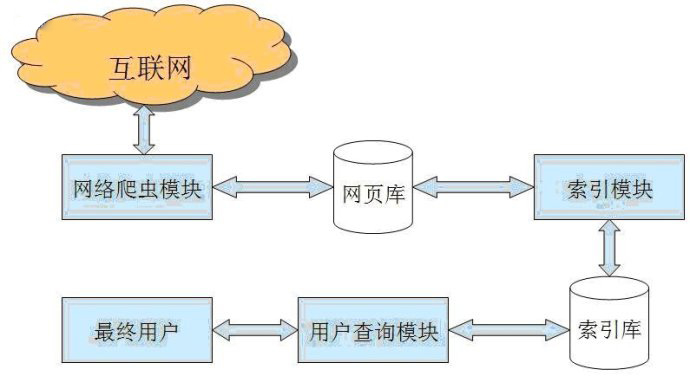
Spider的抓取是搜索引擎內(nèi)容的重要來(lái)源,Spider通過(guò)抓取一個(gè)鏈接不斷的往下抓取,就像是一個(gè)蜘蛛網(wǎng),蜘蛛在網(wǎng)上面不斷的進(jìn)行爬取從而獲得大量的內(nèi)容來(lái)源。
二、篩選、過(guò)濾
蜘蛛將抓取來(lái)的頁(yè)面會(huì)經(jīng)過(guò)不斷的篩選把帶有明顯的欺騙用戶(hù)的網(wǎng)頁(yè),死鏈接,空白內(nèi)容頁(yè)面,沒(méi)有豐富內(nèi)容,文不對(duì)題的垃圾頁(yè)面等進(jìn)行過(guò)濾掉。這些網(wǎng)頁(yè)對(duì)用戶(hù)、站長(zhǎng)和百度來(lái)說(shuō),都是沒(méi)有足夠的價(jià)值得垃圾頁(yè)面,是為了避免為用戶(hù)和您的網(wǎng)站帶來(lái)不必要的麻煩,以提高用戶(hù)體驗(yàn)。
三、建立索引
百度對(duì)抓取回來(lái)的內(nèi)容會(huì)逐一進(jìn)行標(biāo)記和識(shí)別,并將這些標(biāo)記進(jìn)行儲(chǔ)存為結(jié)構(gòu)化的數(shù)據(jù),比如網(wǎng)頁(yè)的tag、title、metadescripiton、網(wǎng)頁(yè)外鏈及描述、抓取記錄。同時(shí),也會(huì)將網(wǎng)頁(yè)中的關(guān)鍵詞信息進(jìn)行識(shí)別和儲(chǔ)存,以便與用戶(hù)搜索的內(nèi)容進(jìn)行匹配。
四、展示排序
用戶(hù)輸入的關(guān)鍵詞,百度會(huì)對(duì)其進(jìn)行一系列復(fù)雜的分析,并根據(jù)分析的結(jié)論在索引庫(kù)中尋找與之最為匹配的一系列網(wǎng)頁(yè),按照用戶(hù)輸入的關(guān)鍵詞所體現(xiàn)的需求強(qiáng)弱和網(wǎng)頁(yè)的優(yōu)劣進(jìn)行打分,并按照最終的分?jǐn)?shù)進(jìn)行排列,展現(xiàn)給用戶(hù)。
絡(luò)聯(lián)系人微信二維碼") 掃一掃 加微信咨詢(xún)
掃一掃 加微信咨詢(xún)
絡(luò)logo")
碼圖標(biāo)")